


s-640エンコウのはなし.jpg
—–—–—–
・日本語文字認識ソフト『読んde!!ココ』をずいぶん前に使ったことがありす。今もバージョンアップされているようです。
・オフィスプリンタにも PDFファイル、または DocuWorksファイルに、文字認識するか、しないかの設定があります。
・市販のソフトでは『読み取り革命』などがあり,「AIで劇的に進化(読み取り精度の向上)」などと謳われていたりします。
—–—–—–
ボランティア活動『マルチメディアデイジー図書』の作成に関連して「読み取り革命」に代わる手法はないかと調べていて,
1「フォト」 で 『ひろしま昔ばなし』
2「Snipping Tool」 で 『涙の箱 ハン・ガン (著)』
3. 〃 で 『多面体の模型 ウェニンガー(著)』
で簡単にテキストを取り出す事ができることがわかりました。
—–—–—–
1「フォト」 で 『ひろしま昔ばなし』 (先頭図)
・光学式文字認識(OCR)が強化され,日本語を含む160か国をサポートしているとのこと。検出したテキストをWebで検索する機能も追加されているようです。
(私が未習熟のためか)
・逆順になっている とか
・「川」が「ル」になっている など問題点は残っていますが、これだけの精度ならば十分使える…といった感じです。
フォト_逆順一部誤変換.pdf
http://yamamath.org/wp-content/uploads/2026/03/フォト_逆順一部誤変換.pdf
—–—–—–
2「Snipping Tool」 で 『涙の箱 ハン・ガン (著)』
Snipping Tool_icon.JPG
画像やpdfを表示したところで『窓+sift+s』を同時に押すと「snipping tool」が起動します。
1. 範囲指定してスクリーンショットし
2.「マークアップと共有」ボタンを押し
3.「テキストアクション」を選びます。
4. 全てのテキストをコピーして
5. メモ帳あるいは秀丸などに貼りつけます。
ボランティアでの次の取り組み課題だそうです。ページによってはpdfを-90度回転したり戻したりもありますが,日本語/英語/ハングル 混在していても一瞬でテキスト化して取り出すことができます。なんとかこの新たな手法で取り組めそうです。
涙の箱_韓江_Snipping Tool.JPG

☆ Snipping Tool を使えば,テキストのついていないpdfや,文字を含んだ画像あるいはウェブ画面などから,文字認識(OCR)して容易にテキストを取り出すことができるようになっています。
【 p.s.】「涙の箱」は88ページの本ですが1時間余りでテキスト化を完了しました。勿論全ての点検は必要ですが,これまでのOCRソフトからすれば驚くべき速さと正確さだと感じています。
—–—–—–
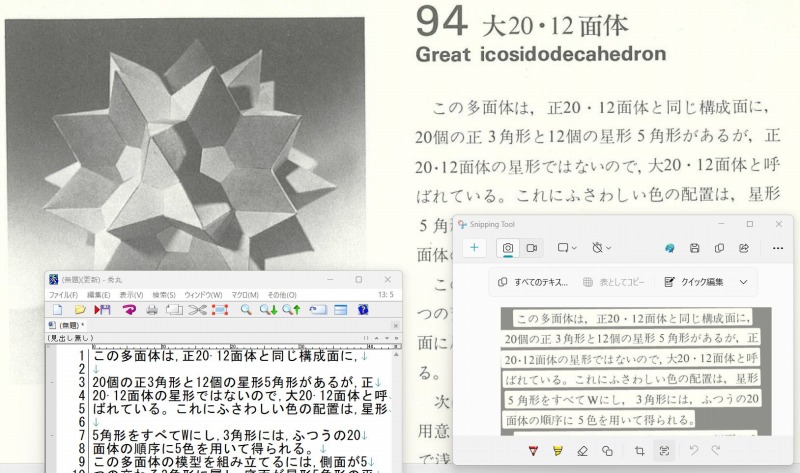
3.「Snipping Tool」 で 『多面体の模型 ウェニンガー(著)』
次の画像は,保存してあった「ウェニンガー№94 大20・12面体」のスキャン結果のpdfを表示し,snipping tool を用いて「スクショ+テキストアクション」でクリップボードに保存された認識結果を秀丸に貼りつけただけのものです。完璧です!
s-800 We94をsnip_to_text.jpg
【数学の話題】